4.††††† ачество данных и св€занные
проблемы
7.††††† лассификаци€ методов кластер-анализа.
9.††††† »ерархические дивизимные процедуры.†
(см. выше)
11.†††††††† ћетоды построени€ размытых кластеров. Ќечеткий кластерный анализ
12.†††††††† »спользование теории графов в
кластер-анализе
13.†††††††† ћетоды поиска модальных значений плотности.
14.†††††††† ѕроверка качества разбиени€ совокупности данных на кластеры.
15.†††††††† Ћокальные и глобальные правила
остановки
17.†††††††† ѕостроение канонических
дискриминантных функций. »нтерпретаци€ коэффициентов
18.†††††††† ѕроверка значимости дискриминантных функций. ќстаточна€ дискриминантна€
способность.
21.†††††††† ѕроцедуры отбора оптимального состава дискриминантных переменных.
22.†††††††† —нижение размерности данных.
ѕостановка задачи и методы решени€
23.†††††††† ћодели и методы факторного анализа.
24.†††††††† ћетод главных компонент
25.†††††††† ‘ундаментальна€ теоpема в
случае коppелиpуемых и некоррелируемых фактоpов.
26.†††††††† лассификаци€ факторов и св€зи между отдельными видами факторов.
28.†††††††† —хема решени€ и основные проблемы факторного анализа.
29.†††††††† √еометрическа€ интерпретаци€
модели факторного анализа
30.†††††††† ѕространство общих факторов и полное фактоpное пpостpанство.
32.†††††††† ритерии оценки числа факторов, подлежащих выделению.
33.†††††††† ѕpоблема общности. ¬ чем она
состоит и как pешаетс€
34.†††††††† ѕроблема вращени€ и пон€тие
наипростейшей факторной структуры
35.†††††††† ÷ель и конечный pезультат
оpтогонального вpащени€.
36.†††††††† ћетоды и критерии в
ортогональном вращении
38.†††††††† »змерение факторов.
39.†††††††† ѕрограммное обеспечение,
используемое дл€ интеллектуального анализа данных
40.†††††††† ћетоды визуализации
многомерных† данных
1.
Data Mining Ц интеллектуальный
анализ данных: определение, жизненный цикл данных, обща€ характеристика
процесса анализа
Data Mining
(Ђƒобычаї, Ђ–аскопка данныхї)
- это процесс, цель которого Ц
обнаружить новые значимые коррел€ции, образцы и тенденции в результате
просеивани€ большого объема хранимых данных с использованием методик
распознавани€ образцов плюс [применение] статистических и математических
методов.
- это исследование и обнаружение
Ђмашиннымиї методами (алгоритмами, средствами искусственного интеллекта) в
сырых данных скрытых знаний, которые ранее не были известны. Ќетривиальны,
практически полезны, доступны дл€ интерпретации человеком.
∆изненный цикл данных:

1.»сточники данных: внутренние
данные, внешние данные, личные данные;
2.’ранилища данных;
3.¬итрины данных;
4.јнализ данных: OLAP, запросы, Data Mining;
5.–езультат: визуализаци€ данных,
решени€, менеджмент знаний;
6.»мпорт в другие системы дл€
обработки: CRM, ERPЕ

1.
ќпределение проблемы;
2.
—бор данных;
3.
¬ыполнение первичной обработки данных;
4.
«апуск модели на выполнение;
5.
»нтерпретаци€ модели и выводы.
2.
Data Mining Ц интеллектуальный
анализ данных: решаемые задачи, типы вы€вл€емых закономерностей и используемые
технологии и алгоритмы.
«адачи, решаемые Data Mining:
Ј
лассификаци€ Ц отнесение входного
вектора (объекта, событи€, наблюдени€) к одному из заранее известных классов.
Ј
ластеризаци€ Ц разделение множества
входных векторов на группы (кластеры) по степени Ђпохожестиї друг на друга.
Ј
–егресси€ Ц установление
зависимости непрерывными входным и выходным векторами.
Ј
јссоциаци€ Ц поиск повтор€ющихс€
паттернов. Ќапример, поиск устойчивых св€зей в корзине покупател€ (market
basket analysis) Ц вместе с пивом покупают орешки.
Ј
—окращение описани€ Ц дл€ визуализации
данных, лаконизма моделей, упрощени€ счета и интерпретации, сжати€ объемов
собираемой и хранимой информации.
Ј
ѕоследовательные шаблоны Ц аналогично задаче ассоциации,
но с учетом временной составл€ющей. Ќапример, поиск причинно-следственных
св€зей.
Ј
ѕрогнозирование Ц аналогично задаче регрессии, но
с учетом временной составл€ющей. Ќапример, прогноз трендов финансовых
показателей.
Ј
јнализ отклонений Ц вы€вление наиболее
нехарактерных паттернов. Ќапример, вы€вление нетипичной сетевой активности
позвол€ет обнаружить вредоносные программы.
¬ литературе можно встретить еще
р€д классов задач. Ѕазовыми задачами €вл€ютс€ первые п€ть. ќстальные задачи
свод€тс€ к ним тем или иным способом.
“ипы вы€вл€емых закономерностей:
Ј
јссоциаци€ Ц высока€ веро€тность
св€зи событий друг с другом (например, один товар часто приобретаетс€ вместе с
другим);
Ј
ѕоследовательность Ц высока€ веро€тность
цепочки св€занных во времени событий (например, в течение определенного срока
после приобретени€ одного товара будет с высокой степенью веро€тности
приобретен другой);
Ј
лассификаци€ Ц имеютс€ признаки,
характеризующие группу, к которой принадлежит то или иное событие или объект
(обычно при этом на основании анализа уже классифицированных событий
формулируютс€ некие правила);
Ј
ластеризаци€ Ц закономерность, сходна€
с классификацией и отличающа€с€ от нее тем, что сами группы при этом не заданы
Ц они вы€вл€ютс€ автоматически в процессе обработки данных;
Ј
¬ременные закономерности Ц
наличие
шаблонов в динамике поведени€ тех или иных данных (типичный пример Ц сезонные
колебани€ спроса на те или иные товары, либо услуги), используемых дл€
прогнозировани€.
»спользуемые технологии и алгоритмы:
Ј
–егрессионный,
дисперсионный и коррел€ционный анализ Ц реализован в большинстве
современных статистических пакетов, в частности, в продуктах компаний SAS Institute, StatSoft и др.
Ј
ћетоды анализа,
базирующиес€ на эмпирических модел€х Ц дл€ анализа в конкретной
предметной области и примен€ютс€ в недорогих средствах финансового анализа.
Ј
ќбнаружение
аномалий/отклонений Ц определение серьезных отклонений от нормального
поведени€.
Ј
ластерные модели †- примен€ютс€ дл€ объединени€ сходных событий
в группы на основании сходных значений нескольких полей в наборе данных. ѕримен€ютс€
различные алгоритмы группировки, например, метод Ђближайшего соседаї.
Ј
ƒеревь€ решений Ц иерархическа€ структура,
базирующа€с€ на наборе вопросов, подразумевающих ответ Ђдаї или Ђнетї. Ќе
способны находить Ђлучшиеї правила в данных (наиболее полные и точные).
Ј
јлгоритмы ограниченного
перебора Ц вычисл€ющие частоты комбинаций простых логических событий в подгруппах
данных.
Ј
Ќейросетевые алгоритмы Ц иде€ которых основана на
аналогии с функционированием нервной ткани и заключаетс€ в том, что исходные
параметры рассматриаютс€ как сигналы, преобразующиес€ в соответствии с
имеющимис€ св€з€ми между Ђнейронамиї, а в качестве ответа, €вл€ющегос€
результатом анализа, рассматриваетс€ отклик всей сети на исходные данные.
Ј
Ёволюционное
программирование Ц поиск и генераци€ алгоритма, выражающего взаимозависимость данных, на
основании изначально заданного алгоритма, модифицирующегос€ в процессе поиска.
Ј
—истемы рассуждений на
основе аналогичных случаев Цне создают каких-либо моделей или правил, обобщающих
предыдущий опыт, произвол при выборе меры близости.
Ј
√енетические алгоритмы Ц критерий отбора хромосом и
используемые процедуры €вл€ютс€ эвристическими и далеко не гарантируют
Ђлучшегої решени€.
Ўкала Ц кортеж из трех элементов <x,ϕ,y>, где† x Ц реальный объект, ϕ Ц гомоморфное отображение
X на Y, y Ц шкала; это правило, в
соответствии с которым объектам присваиваютс€ числа.
Ј
Ќоминальные Ц простейший вид измерений;
качественна€ шкала (шкала наименований); цель Ц вы€вление различий между
объектами разных классов, например, номера машин, телефонов, коды городов. “о
есть символы 1 и 2 в шкальных обозначени€х €вл€ютс€ не числами, а цифрами.
Ј
–анговые (шкалы пор€дка) Ц
шкала, у
которой множество ϕ
состоит из всех монотонно возрастающих допустимых преобразований шкальных
значений. ƒопускает не только различие объектов, как номинальный тип, но
используетс€ и дл€ упор€дочени€ объектов по измер€емым свойствам (во времени, в
пространстве, в соответсвии с каким-либо свойством объекта, которое не
об€зательно точно измер€ть или которое не может быть измерено). Ќапример, шкалы
силы ветра, силы земл€тресени€, сортности товара и т.д.).
Ј
»нтервальные Ц наиболее важна€ шкала;
содержит шкалы, единственные с точностью до множества положительных линейных
допустимых преобразований вида ϕ(x) = ax + b, а > 0, b Ц любое значение. —войство Ц
сохранение неизменных отношений интервалов в эквивалентных шкалах. ѕри переходе
к эквивалентным с помощью преобразований происходит изменение начала отсчета
(параметр b) и масштаба измерений (параметр
а). —охран€ют различие и упор€дочивание измер€емых объектов, как и предыдущие.
ѕример, шкалы температур, врем€ выполнени€ задани€, любые временные и
пространственные характеристики объектов.
Ј
ќтношений (подоби€) - шкала, у которой множество
ϕ состоит из преобразований
вида ϕ(x) = ax, а > 0. —войство Ц сохранение
неизменных отношений численных оценок объектов, то есть во сколько раз свойство
одного объекта превосходит это же свойство другого объекта. ќбразуютс€ из шкал
интервалов фиксированием нулевого значени€ параметра †b: b=0. ѕереход от одной шкалы к другой осуществл€етс€ с
помощью преобразовани€ подоби€. ѕример, измерение массы в кг, футах и т.д.
Ј
–азностей Ц шкалы, единственные с
точностью до преобразований сдвига††† ϕ(x) = x + b; мен€етс€ только начало отсчета.
—войство Ц сохранений разностей численных оценок объектов. ќбразуютс€ из шкал
интервалов фиксированием нулевого значени€ параметра †а: а=1. —охран€ют отношени€ рассто€ний
между парами объектов. ѕример: измерение прироста продукции предпри€тий (в
абсолютных значени€х в текущем году по сравнению с прошлым и т.д.
Ј
јбсолютные Ц шкалы, в которых
единственными допустимыми преобразовани€ми €вл€ютс€ тождественные
преобразовани€ ϕ(x) = x. „астный случай всех других.
ѕример: измерени€ количества объектов, предметов, решений, событий и т.д.
Ј
ѕромежуточные Ц степенна€ axb, логарифмическа€ шкала.
Ј
ƒихотомические Ц содержит только две
категории, например, пол.
“ипы данных:
Ј
ƒанные, состо€щие из записей (Record) Ц представлены набором записей, кажда€ из которых содержит
фиксированный набор атрибутов.
o
Data Matrix Ц представление данных в виде mxn матрицы, где m строк (строка Ц объект) и n столбцов (один столбец Ц атрибут).
o
Document Data Ц каждый документ описываетс€ в виде СtermТ вектора. «начение каждого компонента
Ц множество вхождений соответствующего СtermТ в документ.
o 
o
Transaction Data Ц особый тип данных в виде записей, где кажда€ запись
(транзакци€) включает набор значений, например, список покупок клиента.
Ј
√рафические данные (Graph) Ц данные представлены в виде
графа.
o
World Wide Web Ц интернет;
o
Molecular Structures Ц молекул€рные структуры.
Ј
”пор€доченные данные (Ordered) Ц например,
последовательность транзакций
o
Spatial Data Ц пространственные данные, например, географические;
o
Temporal Data Ц временные данные;
o
Sequential Data Ц последовательности данных;
o
Genetic Sequence Data Ц генетические последовательности данных.
4. ачество данных и св€занные
проблемы.
ƒл€ обработки данных методами Data Mining необходимы качественные
данные. Ќо в реальной жизни мы сталкиваемс€ с проблемами, св€занными с
качеством.
Ј
Ўум Ц св€зан с модификацией
оригинальных значений;
Ј
¬ыбросы Ц объекты данных с
характеристиками, которые значительно отличаютс€ от большинства объектов в
наборе данных.
Ј
ѕропущенные значени€ Ц св€заны с тем, что не
всегда могут быть получены данные, по причине нежелани€ предоставлени€ данных,
или отсутстви€ их. ј также из-за ошибок ввода операторами. —пособы обработки:
исключение объектов из набора данных; вычисление пропущенных значений;
игнорирование пропущ. значений в ходе анализа; замена на возможные значени€ (с
указанием веро€тности)
Ј
ƒупликаты в данных Ц объекты в наборе
данных, которые €вл€ютс€ полными или неполными дупликатами друг друга.
Ќапример, один и тот же человек с разными мейлами. „истка данных: процесс
обработки дупликатов. Ќапример, soundex.
(*посмотреть документацию на
работе*)
лассификаци€ Ц разделение рассматриваемой совокупности объектов
или €влений на однородные, в определенном смысле, группы. ѕри этом термин
Ђклассификаци€ї используетс€ как дл€ самого процесса разделени€, так и дл€
результата.
ѕостановка задачи: формулировка задачи; формализаци€
задачи. ¬ключает также описание статического и динамического поведени€
исследуемых объектов.
лассификаци€ может быть
одномерной (по одному признаку) и многомерной (по двум и более признакам).
ѕравила классификации: (1)в каждом акте делени€ необходимо примен€ть только
одно основание; (2) деление должно быть соразмерным, т.е. общий объем видовых
пон€тий должен равн€тьс€ объему делимого родового пон€ти€; (3) члены делени€
должны взаимно исключать друг друга, их объемы не должны перекрещиватьс€; (4)
деление должно быть последовательным.
–азличают классификации:
≈стественную - по существенным признакам, характеризующим внутреннюю общность
предметов и €влений. »скусственную - по внешнему признаку и служит дл€ придани€
множеству объектов нужного пор€дка. ѕростой - деление родового пон€ти€ только
по признаку и только один раз до раскрыти€ всех видов. —ложной - дл€ делени€
одного пон€ти€ по разным основани€м и синтеза таких простых делений в единое
целое. «адачей классификации часто называют предсказание категориальной
зависимой переменной на основе выборки непрерывных и/или категориальных
переменных.
¬арианты задани€ исходных данных:
Ј
ћатрица Ђобъект-свойствої
- где
каждый элемент матрицы Ц это значение j-го признака у i-го объекта. “о есть строка характеризует некоторый объект в наборе данных.
Ј
ћатрица сходства Ц где каждый элемент матрицы
характеризует сходство объектов Oi и Oj.
Ј
«апись
Ј
ƒокумент
Ј
“ранзакци€
Ј
√раф
Ј
ѕоследовательность
ѕрактическое применение: ?
ћера близости или сходства Ц это величина, имеюща€ предел и
возрастающа€ с возрастанием близости объектов.
”слови€ дл€ выбора меры близости:
симметричность, различимость (aij<>1,если i <> j), тождественность (aii = 1).
Ј
оэффициенты коррел€ции Ц сама€ распространенна€
мера сходства при иследовани€х в области социальных наук. Ќаиболее известный Ц
смешанный момент коррел€ции ( .ѕирсон):

††††††† Xik Ц значение k-ой переменной дл€ i-го объекта;
††††††† ![]() †- среднее значений всех переменных i-го объекта;
†- среднее значений всех переменных i-го объекта;
††††††† P Ц число переменных.
Ђ-ї мера чувствительна к форме за
счет снижени€ чувствительности к величине различий между переменными.
Ђ-ї коррел€ци€, вычисленна€ этим
способом, не имеет статистического смысла, поскольку среднее значение
определ€етс€ по совокупности всевозможных разнотипных переменных дл€ объекта, а
не совокупности объектов.
Ј
ћеры рассто€ни€
(несходства) Ц пользуютс€ широкой попул€рностью. ќбладают своствами: симметричности,
неотрицательности, минимальное значение дл€ двух идентичных объектов.
o ≈вклидово рассто€ние Ц наиболее известна€ мера
рассто€ни€:

dij Ц рассто€ние между объектами i и j, а xik Ц значение к-ой переменной дл€ i-го объекта.
o вадратичное евклидово рассто€ние Ц возведение евклидова
рассто€ни€ в квадрат во избежани€ ивзлечени€ корн€ Ц d2.
o ћанхеттенское рассто€ние (’емминга) Ц
![]()
o ћетрика ћинковского Ц
 , r >= 1
, r >= 1
o –ассто€ние ћахаланобиса (обобщенное рассто€ние) Ц используетс€ в случае
зависимости объектов
![]()
Σ Ц обща€ внутригруппова€
ковариационна€ матрица, Xi и Xj Ц векторы значений переменных дл€ объектов i и j соответственно.
¬о все меры можно ввести вес,
тогда такие меры называютс€ взвешенными.
Ђ-ї ќценка сходства сильно зависит от различий сдвига в
данных. ¬ли€ние переменных с большим средним и отклонением;
ћожно пытатьс€ провести
стандартизацию, но тогда по€вл€етс€ опасность усилить Ђзашумленностьї от плохо
раздел€ющей переменной.
Ј
оэффициенты ассоциативности
(например, коэффициент ∆аккара) Ц примен€етс€ дл€ определени€ сходства между
объектами, описываемыми бинарными переменными. ѕостроение матрицы
ассоциативности между двум€ объектами:
†† 1 0
1 3 0
0 2 1
![]()
Ј
¬еро€тностные коэффициенты
сходства Ц сходство между объектами не вычисл€етс€. ѕри образовании кластеров
вычисл€етс€ информационный выигрыш от объединени€ двух объектов, а затем те
объединени€, которые дают минимальный выигрыш рассматриваютс€ как один объект. Ёта мера пригодна лишь дл€ бинарных
данных.
7.
лассификаци€
методов кластер-анализа.
Ј
»ерархические
агломеративные методы;
Ј
»ерархические дивизимные
методы;
Ј
»теративные методы
группировки;
Ј
ћетоды поиска модальных
значений плотности;
Ј
‘акторные методы;
Ј
ћетоды сгущений;
Ј
ћетоды, использующие
теорию графов.
Ј
»ерархические
агломеративные методы;
o ¬ начале каждый объект
считаетс€ отдельным кластером. «адаетс€ матрица рассто€ний.
o ѕо матрице рассто€ний
определ€ютс€ два кластера, наиболее близкие друг к другу, они объедин€ютс€ и
образуют новый кластер.
o ѕересчитываетс€ матрица
рассто€ний. –азмерность матрицы уменьшаетс€ за счет удалени€ двух строк и двух
столбцов.
o Ўаги 2 и 3 повтор€ютс€ до
тех пор, пока не достигнуто необходимое число кластеров или заданна€ мера
сходства (рассто€ни€). ≈сли услови€ не были заданы, то алгоритм останаливаетс€,
пока все объекты не будут объединены в один кластер.
Ј
»ерархические дивизимные
методы;
o ѕротивоположность
агломеративным методам
o ¬ начале все объекты
принадлежат одному кластеру, а затем этот всеобъемлющий кластер разрезаетс€ на
последовательно уменьшающиес€ Ђломтикиї.
І
ћонотетический кластер Ц группа, все объекты которой
имеют приблизительно одно и то же значение некоторого конкретного признака.
ѕринадлежность к такому лкастеру определ€етс€ по фиксированным признакам.
І
ѕолитетический кластер Ц группа, дл€ принадлежности
к которой достаточно наличи€ определенных сочетаний из некоторого подножества
признаков.
o ѕримен€етс€ в основном дл€
бинарных данных.
Ј
ѕостроение дендрограммы Ц графическое отображение
результатов кластеризации, существенное
преимущество всех иерархических алгоритмов. ѕо горизонтальной оси откладываютс€
номера объектов, по вертикали Ц мера рассто€ни€, т.е. значени€ межклассовых
рассто€ний, при которых произошло объединение классов.
Ј
‘ормула рекуррентного пересчета рассто€ни€ между кластерами:
o ћетод одиночной св€зи или ближайшего соседа Ц рассто€ние между классами
определ€етс€ как рассто€ние между ближайшими членами классов.
![]()
Ђ-ї получение цепных, серпантинных кластеров
Ђ+їприменению метода не мешает наличие Ђсовпаденийї в
данных.
o ћетод полной св€зи или дальнего соседа Ц рассто€ние между классами
определ€етс€ как рассто€ние между самыми удаленными парами объектов. ћетод
создает компактные кластеры в виде гиперсфер.
![]()
o ћетод средней св€зи Ц рассто€ние между классами
определ€етс€ как среднее значение исходных попарных рассто€ний между
элементами, принадлежащими этим двум классам.
![]()
o ћетод медиан Ц рассто€ние между классами определ€етс€ как
рассто€ние между точками с медиальными значени€ми всех показателей объектов,
принадлежащих данным классам.
![]()
o ћетод центроид Ц рассто€ние между классами
определ€етс€ как рассто€ние между центрами т€жести классов. ÷ентр т€жести Ц это
точка со средними значени€ми всех показателей с учетом весов отдельных
элементов.
![]()
o ћетод ”орда Ц метод, оптимизирующий минимальную дисперсию внутри
кластеров. »спользует целевую функцию.
![]()
Ј
Ќедостатки:
o
ќбработка и хранение большой матрицы сходства;
o
–аспределение объектов по кластерам за один проход;
o
»зменение решени€ (иногда значительное) при изменении мартицы сходства.
9.
»ерархические
дивизимные процедуры. †(см. выше)
- итеартивные методы работают
непосредственно с первичными данными.
- просматривают данные несколько
раз в ходе алгоритма.
- не образуетс€ иерархических
кластеров.
- число кластеров должно быть
известно заранее.
ѕараллельные процедуры Ц на классификацию поступают все
объекты
o ћетод -средних (K-means) Ц
ü
»сходное разбиение на k кластеров и вычисление
центров т€жести (средних) этих кластеров;
ü
ѕросмотр всех наборов данных, помещение каждого объекта в кластер с
ближайшим центром т€жести;
ü
¬ычисление новых центров т€жести вновь образовванных кластеров;
ü
Ўаг 2 и 3 повтор€етс€ до тех пор, пока не перестанут мен€тьс€ кластеры.
o ћетод -эталонов- иде€ алгоритма: совокупность
объектов, наход€щихс€ на одинаковом рассто€нии от каждого из k эталонов (€дер), образует компактную группу.
ü
¬ыбираетс€ k эталонов и порог d;
ü
ќбъекут ќi ставитс€ в соответствие код из k двоичных символов: Ђ1ї Ц если рассто€ние до k-го эталона меньше порогового, Ђ0ї - в противном случае.
ü
¬ыборка разбиваетс€ на кластеры, содержащие объекты с одинаковым кодом.
ü
„исло эталонов необ€зательно должно быть равно числу кластеров
ѕоследовательные процедуры Ц на классификацию объекты поступают
по одному или малыми порци€ми.
ѕример:
o ¬ основе алгоритма лежит
предположение, что представители одного класса не могут быть удалены друг от
друга более, чем на заданную пороговую величину;
o Ќа классификацию объекты
поступают по одному;
o 1 шаг: ѕервый объект
объ€вл€етс€ €дром е1 первого класса;
o m-ый шаг: m-ый объект провер€ем по
следующему правилу:
ü
если рассто€ние от объекта до одного из ранее объ€вленных €дер меньше
порогого, то добавл€ем к классу, данного €дра;
ü
если все €дра наход€тс€ дальше порогого значени€, то объ€вл€ем новый класс
и новое €дро.
Ќедостатки:
- проблема локального оптимума:
применение процедуры проверки результата на достоверность;
- требование задавать число
кластеров.
11.
ћетоды
построени€ размытых кластеров. Ќечеткий кластерный анализ
ѕричина возникновени€:
ü
¬ классических методах кластерного анализа примен€етс€ так называемое
двоичное (бинарное) разделение. ќднако часто в реальных данных очень трудно
построить четкие границы между классами. »з-за дискретного характера разбиени€
на классы данные классифицируютс€ некорректно.
Ќечеткие множества:
ü
»спользу€ нечеткие множества, принадлежность выражаетс€ в виде веро€тности
от 0 до1.
ћетоды нечеткого кластерного анализа:
ü Fuzzy C-means
o ќснован на методе k-средних (УHard C-meansФ);
o ¬о все формулы, включающие
в себ€ элемент матрицы разбиени€ включаетс€ коэффициент нечеткости w (fuzzification factor) Ц от 1 (дискретный) до бесконечности (полностью размытые границы);
o
ќбычно
используетс€ w=2.
o Ќедостаток:
І
ѕоиск кластеров определенной формы:
Ј
≈вклидово рассто€ние Ц гиперсферы;
Ј
–ассто€ние ’емминга Ц Ђбриллиантыї;
Ј
–ассто€ние „ебышева Ц гиперкубы
І
Ќеоправданное огрубление результата.
ü ластеризаци€ по √юстафсону- есселю
o ѕоиск кластеров в форме
эллипсоидов;
o ластер характеризуетс€
центроидом и ковариационной матрицей.
ü Fuzzy
C-varieties
o ¬место того, чтобы
выражать рассто€ние между двум€ объектом и центроидом, мы можем представить,
что центроиды Ц это более сложные геометрические конструкции, например, в
методе Fuzzy c-Ellipsoids.
o ластер представл€етс€ в
виде r-мерного множества и определ€етс€
центроидом и набором ортогональных векторов.
ü Possibilistic
Fuzzy C-means (P-FCM)
o ќпределение
объектов-выбросов (атипичных объектов);
o ¬ целевой функции
используетс€ взвешивающий коэффициент β, регулирующий суммарную
принадлежность объектов к кластерам и выбросы образуют отдельный кластер.
ü Noise Clustering
o
¬ы€вление Ђшумаї в
данных;
o ![]() ќпределение специального кластера (кластер Ђшумаї), который
позвол€ет локализовать и поместить Ђшумї в отдельный кластер;
ќпределение специального кластера (кластер Ђшумаї), который
позвол€ет локализовать и поместить Ђшумї в отдельный кластер;
o ¬ целевой функции
используетс€ взвешивающий коэффициент†† ,
определ€ющий рассто€ние между Ђчистымиї данными и кластером Ђшумаї;
o јлгоритм заканчивает
работу с c+1 кластерами.
ü
ƒостоинства:
o ластеризаци€ становитс€
более применимой к реальным данным;
o јнализ граничных объектов
и снижение их вли€ни€ на процесс кластеризации.
ü
Ќедостатки:
o ƒопущение об определенной
форме кластеров;
o јлгоритмы стро€тс€ на
расположении центроидов кластеров, а не совокупности точек в нЄм;
o Ќевозможность обработки
вложенных кластеров (например, вложенных сфер).
12. »спользование теории графов в
кластер-анализе.
o јлгоритм Ђ¬роцлавска€ таксономи€ї - строитс€ кратчайший
незамкнутый путь ( Ќѕ): соедин€ютс€ ребром две ближайшие точки, затем
отыскиваетс€ точка, ближайша€ к любой из уже рассмотренных точек, и соедин€етс€
с ней и т.д. до исчерпани€ всех точек. “акой способ повтор€ет метод ближнего
соседа. ¬ найденном Ќѕ отбрасывают k-1 самых длинных дуг и
получают k классов.
o јлгоритм Ђ—лучайное разрезание графа сходстваї - из полного графа сходства
случайным образом производитс€ выборка вершин, между которыми строитс€ Ќѕ.
«апоминаютс€ все его звень€ и частоты их повтор€емости. «вень€ с частотами,
большими n (задаваемый параметр), рассматриваютс€
как межклассовые и отбрасываютс€. т.е. происходит разрезание графа. ѕроцедура
основана на том, что межклассовых рассто€ний всегда больше, чем
внутриклассовых. јлгоритм €вл€етс€ первой процедурой Ђслучайной кластеризацииї,
перспективной дл€ больших массивов данных.
Ђ+ї возможность графического представлени€.
13.
ћетоды
поиска модальных значений плотности.
Ёти методы рассматривают кластер
как область пространства с Ђвысокойї плотностью точек по сравнению с
окружающими област€ми. ќни Ђобследуютї пространство в поисках скоплений данных,
которые и представл€ют собой области высокой плотности
o ћетоды, основанные на кластеризации по одиночной св€зи Ц преп€тствуют образованию
цепочек. ¬ методах поиска модальных значений плотности используетс€ правило:
отдавать предпочтение образованию нового кластера, а не присоединению объекта к
существующему. ѕример, модальный анализ.
Ђ-ї зависимость от выбора шкал;
Ђ-ї кластеры образуютс€ сферической формы.
o ћетоды разделени€ Ђсмесейї многомерных веро€тностных
распределений Ц смесь Ц это совокупность выборок, представл€ющих различные совокупности
объектов. –ешаетс€ задача ращеплени€ смеси: по выборке классифицируемых
наблюдений построить статистические оценки дл€ числа компонентов смеси k; построить статистические оценки их априорных
веро€тностей; дл€ каждого из компонентов построить функции плотности. ƒанна€ постановка €вл€етс€ наиболее
полной. „асто, зна€ число компонент, нудно определить лишь функции плотности.
ü
ѕроцедуры, работающие Ђот
оценивани€ параметров смеси к классификацииї - в начале наход€тс€ оценки неизвестных параметров, например, методом
максимального правдоподоби€.
ѕример: ≈ћ-алгоритмы Ц Ќазвание происходит от Estimation Цоценка параметров, Maximization Ц максимизаци€ функции
правдоподоби€.
ќценка происходит на основании
допущений:
o лассификаци€ производитс€
на основе смеси распределений;
o —месь состоит из
известного числа классов k;
o –аспределение признаков в
одном классе представлено одним распределением;
o јприорные веро€тности
классов неизвестны.
«адача оценивани€ параметров смеси
по выборке очень сложна. ќдна из главных проблем Ц выбор числа классов
анализируемой смеси k.
—ам алгоритм состоит в том, чтобы
определить принадлежность объекта к классу, функци€ правдоподоби€ которого
максимальна.
ü
ѕроцедуры, работающие Ђот
классификации к оцениваниюї -
ѕример: SEM-алгоритмы - Ќазвание происходит от Estimation Цоценка параметров, Maximization Ц максимизаци€ функции
правдоподоби€, Stochastique Ц статистическое
моделирование.
»де€ алгоритма состоит в том, что
задача классификации начинаетс€ с разбиени€ совокупности классифицируемых
наблюдений на k подвыборок, а затем дл€ каждой
подвыборки примен€етс€ оценка параметров, после чего уточн€етс€ разбиение.
Ђ-ї Ёти методы основаны на
статистической модели, и далеко не дл€ всех задач смесь может быть разделена.
14.
ѕроверка
качества разбиени€ совокупности данных на кластеры.
Ј ¬изуальные средства оценки степени разнесенности и
компактности выделенных групп объектов Ц отображение объектов в одно-,
дву-, трехмерном пространстве с указанием их групповой принадлежности в виде
гистограмм или диаграмм рассеивани€. “акже это могут быть графики средних.
Ј ќценка качества классификации с помощью функционалов
качества Ц провер€ютс€ неформальные требовани€ к образованному разбиению: внутри группы
объекты должны быть тесно св€заны между собой; объекты различных групп должны
быть далеки друг от друга; распределение
объектов по кластерам должно быть равномерным.
o
—умма квадратов рассто€ний
до центров классов (внутриклассовый разброс)
![]()
![]() †- вектор значений переменных дл€ i-го объекта;
†- вектор значений переменных дл€ i-го объекта;
![]() - центр т€жести l-ой группы;
- центр т€жести l-ой группы;
nl Ц число элементов l-ой группы;
![]() †- рассто€ние между i-ым объектом и центром l-го кластера.
†- рассто€ние между i-ым объектом и центром l-го кластера.
o
—умма внутриклассовых
рассто€ний между объектами
![]()
o
—уммарна€ внутриклассова€
дисперси€
![]()
o
ќбъ€сненна€ дол€ общего
разброса
І
ќбщее рассеивание
![]()
![]() - общий центр т€жести l-ой группы;
- общий центр т€жести l-ой группы;
І
ћежклассовый разброс
![]()
І
T = 1 ЦSW/S, 0 <= T <= 1. „ем больше “, тем больше дол€ общего разброса точек
объ€сн€етс€ межклассовым разбросом, и можно считать, что тем лучше качество
разбиени€.
o
оэффициент ƒэвиса-Ѕолдина;
o
оэффициент RMSSTD.
Ј
¬ы€вление среди полученных
групп кластеров и сгущений Ц проводитс€ анализ образованных групп на наличие в них
кластеров и сгущений (чем больше их, тем лучше):
o ластером Ц называетс€ группа объектов Gi така€, что выполн€етс€ неравенство
![]()
o —гущением Ц называетс€ группа объектов Gi, если максимальный квадрат рассто€ни€ объектов из Gi† до центра группы
меньше среднего квадрата до общего центра
![]()
Ј
ћетод проверки на основе
кофенетической коррел€ции Ц данный метод используетс€ только дл€ иерархических
агломеративных методов. онефетическа€ коррел€ци€ показывает, насколько хорошо
сходство (или несходство) между объектами представл€етс€ дендрограммой,
полученной с помощью агломеративных иерархических методов. —троитс€ вторична€
матрица сходства между всеми парами объектов, и коррел€ци€ между значени€ми
исходной матрицы и вторичной матрицы Ц и есть конефетическа€ коррел€ци€.
Ђ-ї содержание информации в этих двух матрицах различно.
Ј
“есты значимости дл€
признаков, используемых при создании кластеров Ц применение многомерного
дисперсионного анализа признаков, дл€ вы€снени€, €вл€етс€ ли разбиение на
кластеры значимым. »спользуетс€ критерий ‘ишера.
Ј
“есты значимости дл€
внешних признаков Ц метод основан на применении многомерного дисперсионного анализа признаков,
не участвующих в кластерном анализе.
Ђ-ї очень дорогосто€щий.
Ј
ћетод проверки, основанный
на повторной выборке Ц метод основан на том, что к различным выборкам из одной и
той же генеральной совокупности примен€етс€ одинаковый метод кластерного
анализа. ќднако данный метод не доказывает обоснованность решени€, а только
позвол€ет оценить степень устойчивости кластерного решени€.
Ј
ћетоды ћонте- арло Ц
o ƒл€ оценки результатов классификации: генерируетс€
множество искусственных данных, которые не принадлежат исходной выборке, но
обладают схожими характеристиками. ƒалее к каждому из наборов данных
примен€етс€ один и тот же метод кластерного анализа, полученные результаты
сравниваютс€ с помощью тестов значимости, основанные на F-отношении. » делаетс€ вывод об
обоснованности числа выделенных кластеров.
o ƒл€ оценки самих методов кластеризации Ц генерируетс€
выборка с заранее известным числом кластеров, и запускаетс€ метод
кластеризации. ƒалее оцениваетс€ веро€тность ошибки классификации, котора€ и
определ€ет качество разбиени€ анализируемым методом.
15. Ћокальные и глобальные правила
остановки.
ритерии определени€
предпочтительного числа кластеров (только дл€ иерархических методов):
Ј
Ћокальные Ц так как оценивает критерий
остановки при k=1
o
Duda и Hart предложили критерий,
основанный на следующем отношении:
![]()
где w[2] Ц сумма квадратов внутрикластерных
рассто€ний в случае, когда данные распределены по двум кластерам;
w[1] Ц сумма квадратов
внутрикластерных рассто€ний в случае одного кластера.
√ипотеза о существовании
единого кластера данных отвергаетс€, если значение критери€ F1 меньше, чем критическое
значение:
![]()
n Ц число объектов дл€ классификации,
р Ц число признаков,
z1-α Ц квантиль стандартного
нормального распределени€ уровн€ 1-α.
“ест отвечает на вопрос,
есть ли вообще структура(кластеры) в данных или они однородны.
o
Beale предложил другую
статистику:

где все обозначени€ смотри
выше.
ƒанный критерий имеет
распределение ‘ишера. ќсновна€ гипотеза состоит в постулировании одного
кластера, и нет оснований еЄ прин€ть, если значение критери€ больше
критического уровн€ статистики.
’от€ данные критерии решают вопрос
относительно двух кластеров, их можно примен€ть не только на последнем шаге
иерархического метода, но и на предыдущих.
Ђ-ї ограниченность сравнени€ и
необходимость задани€ уровн€ значимости (постулируетс€ возможность наличи€
ошибки)
Ј
√лобальный Ц Calinski и Harabasz предложили следующий критерий:
![]() ,
,
где B, W Ц матрица межкластерных и
внутрикластерных сумм квадратов рассто€ний,
k Цчисло кластеров.
ћаксимальное значение критери€
указывает на наиболее веро€тное число кластеров. ѕри проведении иерархического
кластерного анализа на каждом шаге определ€етс€ значение критери€ и находитс€
число кластеров k, при
котором F3
оптимально
(максимально).
Ђ-ї правило не определено при k=1, то есть не исследуетс€
оптимальность при отсутствии разбиени€, а значит не решаетс€ вопрос Ц а должны
ли вообще разбиватьс€ данные.
ƒискриминантный анализ Ц совокупность алгоритмов,
порождающих на основании предположений и выборки конкретное правило
классификации. ќсновным предположением ƒј €вл€етс€ то, что существует две или
более групп, которые по некоторым переменным отличаютс€ друг от друга.
¬ ходе анализа решаетс€ две
задачи:
Ј
»нтерпретаци€ - описание аналитически или графически различий между
объектами разных групп;
Ј
–азделение объектов по группам Ц построение правил классификации дл€ новых
объектов.
ƒискриминантные переменные Ц характеристики, примен€емые дл€
того, чтобы отличить один класс от другого. Ёти переменные должны измер€тьс€
либо по интервальной шкале, либо по шкале отношений.
ƒопущени€ классического ƒј:
Ј
ƒолжно быть два или более классов: g>=2;
Ј
ѕо крайней мере два объекта в каждом классе: ni>=2;
Ј
Ћюбое число дискриминатных переменных при условии, что оно не превосходит
общее число объектов минус 2: 0 < p < (n-2);
Ј
Ќи одна переменна€ не может быть линейной комбинацией других переменных,
отсюда следует линейна€ независимость ƒѕ;
Ј
овариационные матрицы дл€ генеральных совокупностей равны между собой дл€
различных классов;
Ј
«акон распределени€ дискриминатных переменных дл€ каждого класса €вл€етс€
многомерным нормальным, т.е. кажда€ переменна€ имеет нормальное распределение
при фиксированных остальных переменных.
Ёти допущен€ фундаментальны дл€
ƒј. ≈сли экспериментальные данные дл€ некоторой конкретной задачи не вполне
удовлетвор€ют этим предположени€м, то статистические выводы не будут точным
отражением реальности и следует дополнительно решать вопрос о целесообразности
этих процедур.
17. ѕостроение канонических
дискриминантных функций. »нтерпретаци€ коэффициентов.
аноническа€ дискриминантна€ функци€ Ц линейна€ комбинаци€ ƒѕ
и удовлетвор€юща€ определнным услови€м.
![]()
fkm Ц значение канонической
дискриминатной функции дл€ m-го объекта в k-ой группе;
Xikm Ц значение i-й ƒѕ у m-го объекта в группе k;
ui†
- коэффициенты, обеспечивающие выполнение требуемых условий.
оэффициенты u† дл€ первой
функции выбираютс€ таким образом, чтобы еЄ средние значени€ дл€ различных
классов как можно больше отличались друг от друга. оэффициенты дл€ второй
функции выбираютс€ также, но с дополнительным условием: значени€ второй функции
не должны коррелировать с первой и т.д. ћаксимальное число ƒ‘ равно числу
классов минус один, или числу ƒѕ. ¬ зависимости от того, кака€ из этих величин
меньше.
ќсновные принципы получени€ коэффициентов u - †дл€ этого
необходимо ввести статистический критерий дл€ измерени€ степени различий между
объектами. ¬вод€тс€ три матрицы:
Ј
ћатрица “ общегруппого
разброса
![]()
![]() †- среднее значение переменной по
всем классам.
†- среднее значение переменной по
всем классам.
≈сли разделить каждый элемент
матрицы на (n-1), получим ковариационную
матрицу. ƒалее если разделить каждый элемент†
на квадратный корень двух соответствующих диагональных элементов, то
получим коррел€ционную матрицу. Ќо в ƒј чаще примен€ют матрицу “.
Ј
ћатрица W внутригруппового разброса Ц отличаетс€ от “ тем, что еЄ
элементы определ€ютс€ средними значени€ми переменных дл€ отдельных классов, а
не общими средними.
![]()
“акже можно
получить ковариационные и коррел€ционные матрицы дл€ групп.
Ј
ћатрица ¬ межгруппового
разброса: B = T Ц W.
ќдин из методов поиска наилучшей
дискриминации данных заключаетс€ в нахождении такой ƒ‘, котора€ бы
максимизировала отношение межгруппого разброса к внутригрупповому
††††††††††††††††††††††† ![]()
ƒалее решаетс€ система уравнений:

λ Ц собственное число
νi Ц последовательность р коэффициентов ƒ‘.
»звестны только b, w. Ќаход€т собственное
значение и v. ƒалее находим коэффициенты ƒ‘:
![]()
Ќормировка дел€етс€ дл€ того,
чтобы оси брали начало координат от главного центроида. (?)
»нтерпретаци€ ƒ‘:
ѕодставл€€ ƒѕ в ƒ‘, мы получаем
координаты объекта в пространстве ƒ‘, и сможем сравнивать насколько далеки или
близки объекты по отношению друг к другу.
ћожно отобразить объекты из
выборки на графиках дл€ визуального анализа, но в случае большого количества
ƒ‘ это становитс€ сложно.
18.
ѕроверка
значимости дискриминантных функций. ќстаточна€ дискриминантна€ способность.
ƒл€ проверки значимости ƒ‘
существуют следующие подходы:
Ј
—обственное значение
λ Ц
чем больше это значение, тем больше групп будет раздел€ть соответствующа€
функци€.
Ј
ќтносительное процентное
содержание Ц собственное значение делитс€ на общую сумму. Ётот показатель показывает
насколько функци€ слабее по сравнению с другими.
Ј
оэффициент канонической
коррел€ции Ц мера св€зи между группами и ƒ‘. Ќулевое значение Ц отсутствие св€зи,
большее значение Ц сильна€ св€зь. аноническа€ коррел€ци€ отражает реальную
полезность ƒ‘.
Ј
ќстаточна€ дискриминантна€
способность Ц способность переменных различать классы, если исключить информацию с
помощью ранее вычисленных функций. ≈сли эта величина мала, то дальше нет смысла
искать ƒ‘. ƒл€ получени€ ќ—ѕ используют Λ-статистику ”илкса Ц мера
различий между классами по нескольким переменным. „ем она ближе к нулю, тем
выше различение, чем ближе к 1, тем хуже различимость.
Ј
“ест значимости χ2
Ц на
основе статистики ”илкса получим значение статистики χ2..
‘ишер предложил примен€ть дл€
классификации линейную комбинацию ƒѕ, котора€ максимизирует различи€ между
классами, но минимизирует дисперсию внутри классов:
![]()
hk †- значение функции дл€ класса k;
bki Ц коэффициенты, которые необходимо
определить.
ќбъект относ€т к тому классу, дл€
которого получитс€ наибольшее значение функции. оэффициенты классифицирующих
функций обычно не интерпретируютс€, и точное значение функций такж не важно,
главное различимость значений дл€ разных классов.
“акие функции называют простыми классифицирующими функци€ми.
ѕравила тестируютс€ на тестовой
выборке и строитс€ матрица классификации
Ц таблица, строки соответствуют исходным группам, а столбцы Ц полученным
после классификации.
20.
ѕостроение
правила классификации на основе рассто€ни€ ћахаланобиса и апостериорной
веро€тности.
ќбобщенные функции рассто€ни€ и веро€тность
принадлежности к классу:
ћахаланобиса предложил обобщенную меру рассто€ни€, а именно
квадрат рассто€ни€ от точки ’ до центроида данного класса Gk.
![]()
ѕосле вычислени€ рассто€ни€ до
каждого класса объект относитс€ в группу наименьшим D2. ѕредполагаетс€ равкнство ковариационных матриц классов.
¬еро€тность принадлежности к классу:
ќтнос€ объект к ближайшему классу,
мы не€вно приписываем его к тому классу, дл€ которого он имеет наибольшую
веро€тность принадлежности. ƒл€ любого объекта сумма этих веро€тностей по всем
классам не об€затетельно равна 1. ќднако можно сделать предположение о том, что
объект должен принадлежать одной из групп, тогда можно вычислить апостериорную
веро€тность принадлежности дл€ любой из групп.

21.
ѕроцедуры
отбора оптимального состава дискриминантных переменных.
ѕошаговый дискриминантный анализ
примен€етс€ дл€ выбора хороших дискриминаторов из ƒѕ, а также дл€ ранжировани€
ƒѕ по степени их полезности. Ќаиболее широко используемый метод отбора
переменных основан на следующем критерии отбора Ц на отношении внутренней
обобщенной дисперсии к общей обобщенной дисперсии дл€ отбираемых переменных.
ѕримен€етс€ Λ-статистика ”илкса:
![]()
«начение, близкое к 1, указывает
на то слабое разделение между группами, в то врем€ как малое значение на
хорошее разделение между группами.
ƒл€ оценки значимости изменен舆 Λ в результате добавлени€ переменной
примен€ют статистику ‘ишера F.
—уществует два вида
последовательного отбора:
Ј
F-статистика включени€ Ц
оценивает улучшение различени€ от использовани€ рассматриваемой переменной по сравнению
с различением достигнутым с помощью других уже отобранных. —тастика провер€етс€
на значимость Ц так как не должна быть мала;
Ј
F-статистика исключени€ Ц
оценивает значимость ухудшени€ различени€ после удалени€ переменных из списка
уже отобранных. „асто эта процедура проводитс€ с целью ранжировани€ переменных,
так как она удал€ет шаг за шагом почти все переменные из модели.
“акже вводитс€ пон€тие толерантности Ц толерантность дл€
включени€ ƒѕ равна единице за вычетом квадрата еЄ внутригрупповой коррел€ции с
текущими включенными переменными. ≈сли провер€ема€ переменна€ €вл€етс€ линейной
комбинацией одной или нескольких отобранных ранее переменных, то еЄ
толерантность или равна, или близка к нулю. ¬ качестве критери€ используют
рассто€ние ћахаланобиса.
22. —нижение размерности данных. ѕостановка
задачи и методы решени€.
—нижение размерности обусловлено:
Ј
Ќагл€дное представление
(визуализаци€) Ц проецирование в трех-, двухмерное пространство;
Ј
Ћаконизм исследуемых
моделей Ц св€зано с необходимостью† упрощени€
счета и интерпретации полученных статистических результатов;
Ј
—жатие объемов хранимой
статистической информации Ц без видимых потерь в информативности сжатие хранимых
данных в матрицах.
Ј
”странение дублировани€
информации и незначимых признаков.
«адача заключаетс€ в определении такого набора признаков P, найденного в классе F допустимых преобразований
исходных данных показателей, что
![]()
ћетоды:
Ј
ћетод главных компонент Ц в процессе вычислени€
получают все главные компоненты и их число первоначально равно числу исходных
признаков; постулируетс€ возможность полного объ€снени€ дисперсии через
полученные компоненты.
Ј
ћетоды факторного анализа
Ц
дисперси€ признаков здесь не объ€сн€етс€ в полном объеме, признаетс€, что часть
дисперсии остаетс€ нераспознанной как характерность. ѕроцесс выделени€ факторов
последователен и может быть прерван на любом шаге, если прин€то решение о
достаточности дисперсии исходных признаков.
23.
ћодели
и методы факторного анализа.
Ј
ћодель классического
факторного анализа Ц требует наилучшее воспроизведение коррел€ции;
Ј
ћодель главных компонент Ц требует максимально
возможный суммарный вклад в дисперсию;
Ј
ћодель современного
факторного анализа Ц совокупность методов, вы€вл€ющих скрытые характеристики в данных.
ќбща€ цель Ц определение факторных нагрузок.
ћодель его проста:
![]() † i=1Еn
† i=1Еn
где каждый из наблюдаемых
признаков линейно зависит от r некоррелированных между
собой новых комопонент p. ажда€ очередна€
компонента€ дает макисмально возможный вклад в суммарную дисперсию параметров.
25.
‘ундаментальна€
теоpема в случае коppелиpуемых
и некоррелируемых фактоpов.
Ћ.“эрстоуном равенства R = ACAT† и R = ACAT названы
фундаментальной теоремой факторного анализа. — Ц €вл€етс€ матрицей коэффициентов коррел€ции между факторами.
≈сли постулируютс€ ортогональные факторы, то — становитс€ единичной матрицей.
‘ундаментальна€ теорема утверждает, что коррел€ционна€
матрица† R†
может быть воспроизведена с помощью факторного отображени€ ј и коррел€ции между факторами.
26.
лассификаци€
факторов и св€зи между отдельными видами факторов.
Ј
√енеральный Ц все его нагрузки
значительно отличны от 0 (больше 0,6).
Ј
ќбщий Ц хот€ бы две его нагрузки
значительно отличны от 0. √енеральный фактор ј €вл€етс€ частным случаем общего
фактора.
Ј
’арактерный Ц только одна нагрузка
значимо отличаетс€ от 0.
27.
—оставл€ющие
полной дисперсии переменной (общность, хаpактеpность,
спецефичность, надежность).
![]()
hi2 - ![]() †- сумма квадратов нагрузок общих
факторов или общность Ц та часть
полной (единичной) дисперсии, которую можно приписать общим факторам.
†- сумма квадратов нагрузок общих
факторов или общность Ц та часть
полной (единичной) дисперсии, которую можно приписать общим факторам.
ui2 Ц 1 - hi2 Ц дол€ дисперсии, котора€
соответствует квадрату нагрузки определенного фактора ui2 и называетс€ характерностью, т.е. та часть дисперсии, котора€ не св€зана с общими
факторами.
’арактерность делитс€ на:
Ј
—пецифичность ![]() †- та дол€ единичной дисперсии,
котора€ не св€зана с общими факторами и присуща лишь одной определенной
переменной.
†- та дол€ единичной дисперсии,
котора€ не св€зана с общими факторами и присуща лишь одной определенной
переменной.
Ј
![]() †- дисперси€, обусловленна€ ошибкой.
†- дисперси€, обусловленна€ ошибкой.
††††† †Ќадежность Ц специфичность + общность.
28.
—хема
решени€ и основные проблемы факторного анализа.
—хема факторного анализа:

ѕроблемы:
Ј
1 ќбщности Ц получение значени€ оценок
общностей, которые проставл€ютс€ по главной диагонали коррел€ционной матрицы R и получаетс€ редуцированна€ матрица Rh.
Ј
2 ‘акторов Ц извлечение факторов из Rh и получение матрицы ј.
Ј
3 ¬ращени€ Ц выбор одной из большого
числа матриц ј, которые одинаково хорошо воспроизвод€ть Rh=јј“
Ј
4 ќценка факторов Ц оценка значени€ факторов
дл€ каждого индивидуума.
29. √еометрическа€ интерпретаци€
модели факторного анализа.
÷елью факторного анализа €вл€етс€ снижение
размерности данных за счЄт создани€ новых характеристик объектов на основе
исходных. ¬ геометрическом смысле объекты €вл€ютс€ точками в многомерном
пространстве исходных характеристик. ¬ геометрическом смысле, целью факторного
анализа, €вл€етс€ поиск проекций этих объектов в другие пространства. ѕричем
такие пространства, в которых количество осей будет меньше чем в исходном
пространстве при минимальной потере информации о различи€х (“оесть не значимые
потери о различи€х).
30.
ѕространство
общих факторов и полное фактоpное пpостpанство.
ѕространство общих факторов - пространство наименьшей
размерности в котором можно представить m переменных в виде
векторов. Ћюбое другое пространство с меньшей размерностью не смогло бы
включить в себ€ все переменные. Ћюбое пронстранство большей размерности,
обладало бы большими, чем это необходимо возможност€ми. –азмерность ѕќ‘ соответствует
рангу матрицы исходных данных или ранку коррел€ционной матрицы.
¬ геометрической интерпретации в пространстве общих
факторов координатные оси €вл€ютс€ факторами, а вектора† представл€ют переменные. оординатные оси
стандартизованы и равн€ютс€ 1, т.к. дисперси€ фактора должна равн€тс€ еддинице.
ѕример
ѕространство общих факторов дл€ матрицы A=![]()
![]() имеет вид
имеет вид 
ƒлина вектора, представл€ющего переменную в общем
факторном пространстве равна корню из общности.
 †
†
Ќаибольша€ возможна€ длина равна 1. ѕри
геометрической интерпретации длина вектора укащывает на то, кака€ дол€
единичной дисперсии каждой переменной €вл€етс€ общей с факторами.
ѕолное фактоpное пpостpанство. ƒанное пространство
образовано столбцами матрицы F (содержит нагрузки общих и
характерных факторов), представл€ющих координатные оси в этом пространстве. “.к
данное пространство нат€нуто как на общие, так и на характерные факторы, то
пространство общих факторов €вл€етс€ подпространством полного факторного
пространства. ƒлину вектора в полном факторном пространстве можно выразить: 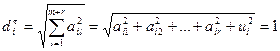
31. ѕроблема факторов. ¬ыделение
факторов с помощью метода главных компонент. ƒругие методы решени€.
ѕроблема факторов состоит в установлении числа и
вида осей координат, необходимых дл€ отображени€ коррел€ции m переменных. —уществует несколько вариантов решени€
данной проблемы: A. многофакторные решени€: метод главных факторов,
центроидный метод. B. метод выделени€ факторов
(однофакторный, бифакторный и т.д.). C. новые методы решени€,
основанные на статистических подходах (метод максимального правдоподоби€,
альфа-факторный анализ).
ѕри любых способах решени€ этой задачи, ввод€тс€
ограничени€, чтобы однозначно определить систему равенств: ![]() . ” каждого метода есть свои ограничени€, введение кот. позвол€ет получить
однозначное решение. ¬
большинстве случаев. исп. методы первой группы.
. ” каждого метода есть свои ограничени€, введение кот. позвол€ет получить
однозначное решение. ¬
большинстве случаев. исп. методы первой группы.

ѕри решении задачи измерени€ трех нормально распределенных
параметров у n индивидуумов, получаетс€ ситуаци€
(рис.1), где n точек сосредоточены в трехмерном
пространстве с трем€ ос€ми переменными X,Y,Z в облаке вокруг общего
центра т€жести. Ёто облако точек наблюдений в общем случае имеет овальную форму
и называетс€ эллипсоидом. ¬ частном случае, когда во всех трех направлени€х
дисперси€ одинакова по величине, получают шар.
Ќа рис. изображено овальное тело с трем€ секущими
плоскост€ми (различно заштрихованными), проход€щими через центр т€жести. ќси
координат исходных, переменных X, Y, Z €вл€ютс€ более или менее
произвольными. ќчевидно, что имеетс€ бесконечно много систем координат, в
которых можно изобразить наблюдаемые точки. ќдна из них представл€ет интерес.
Ёто система координат главных осей:† Х первой главной осью λ1
€вл€етс€ самый длинный диаметр овального тела; Х второй главной осью λ2 €вл€етс€ самый длинный диаметр в
плоскости, ортогональной к первой главной оси и проход€щей через центр т€жести
системы (заштрихована вертикально); Х треть€ главна€ ось λ3
в трехмерном случае перпендикул€рна к первой и второй главным ос€м и проходит
через центр т€жести.
¬ геометрическом плане метод главных факторов состоит в том, что: Х
определ€ют самую длинную ось эллипсоида ќна €вл€етс€ первой главной осью,
котора€ должна пройти через центр т€жести, на рис.1 эта ось обозначена буквой λ1. Х устанавливают подпространство - в
данном случае плоскость, - которое перпендикул€рно к первой главной оси и
которое проходит через центр т€жести (на рис.1 заштриховано вертикально). ¬
этом подпространстве находитс€ следующа€ по величине ось скоплени€ точек и т.
д., пока не будут определены последовательно все главные оси.
ƒлины главных осей пропорциональны величинам дисперсий в направлении
соответствующей главной оси. — помощью метода главных факторов устанавливаютс€
направлени€ этих осей относительно первоначальной системы координат. √лавные
оси соответствуют факторам, которые должны быть лишь надлежащим образом
пронормированы, чтобы выполн€лось требование единичной дисперсии факторов.
ѕереход от системы координат XYZ к системе λ1λ2λ3
соответствует геометрическому решению задачи выделени€ факторов,
осуществл€емому с помощью метода главных факторов. Ётот переход от одной
системы координат к другой без потери информации на практике большей частью
возможен лишь тогда, когда определ€ютс€ все главные компоненты, т. е. дл€ m
переменных определ€ют m главных компонент.
јлгебраическое
решение.
лассическа€ модель ![]() . ѕредположим, что
. ѕредположим, что ![]() , и считаем
, и считаем ![]() †известной и дл€ вывода приравниваем
к 0. Ќеобходимо реш. систему уравнений:
†известной и дл€ вывода приравниваем
к 0. Ќеобходимо реш. систему уравнений: ![]() . ”слови€ дл€ реш. системы уравнений:
. ”слови€ дл€ реш. системы уравнений:
- сумма квадратов нагрузок первого фактора должна
составл€ть максимум от полной дисперсии: ![]() ;
;
- сумма квадратов нагрузок второго фактора должна
составл€ть максимум оставшейс€ дисперсии т т.д.
Ќеобходимым и достаточным условием существовани€
нетривиального решени€ этой системы €вл€етс€ равенство 0 детерминанта матрицы
коэффициентов этих уравнений.
32.
ритерии
оценки числа факторов, подлежащих выделению.
 1) јнализ
долей дисперсий 1.¬ыдел€етс€ такое кол-во факторов, на которое в сумме
приходитс€ 90% полной дисперсии.(на рис. Ц 3 фактора) 2. ¬ыделить только те
факторы, дисперси€ каждого из которых составл€ет более 5% полной дисперсии (на
рис. Ц 4 фактора). ритерий айзера-ƒикмана: факторы, вклады которых в
полную дисперсию (сумма квадратов факторных нагрузок; собственное значение)
меньше 1 не должны выдел€тьс€
1) јнализ
долей дисперсий 1.¬ыдел€етс€ такое кол-во факторов, на которое в сумме
приходитс€ 90% полной дисперсии.(на рис. Ц 3 фактора) 2. ¬ыделить только те
факторы, дисперси€ каждого из которых составл€ет более 5% полной дисперсии (на
рис. Ц 4 фактора). ритерий айзера-ƒикмана: факторы, вклады которых в
полную дисперсию (сумма квадратов факторных нагрузок; собственное значение)
меньше 1 не должны выдел€тьс€
 2)јнализ
собственных значений. ритерий отсеивани€( аттела).
јнализируетс€ графическое изображение всех собственных значений коррел€ционной
матрицы, которые нанос€тс€ в пор€дке убывани€. ≈сли правую часть кривой, на
которой раполагаютс€ точки, можно выровн€ть по пр€мой, то выдел€ютс€ все
факторы, которые не лежат на пр€мой + первый на пр€мой.(на рис. Ц выдел€етс€ 5
факторов)
2)јнализ
собственных значений. ритерий отсеивани€( аттела).
јнализируетс€ графическое изображение всех собственных значений коррел€ционной
матрицы, которые нанос€тс€ в пор€дке убывани€. ≈сли правую часть кривой, на
которой раполагаютс€ точки, можно выровн€ть по пр€мой, то выдел€ютс€ все
факторы, которые не лежат на пр€мой + первый на пр€мой.(на рис. Ц выдел€етс€ 5
факторов)
3)ќценка остатков коррел€ций.
≈сли все остаточные коэф-ты в матрице остатков незначимо отличаютс€ от 0, то
нет смысла в выделении нового фактора
‘акторов должно быть меньше, чем исх. переменных минимум в 2 раза.
33. ѕpоблема общности. ¬ чем она
состоит и как pешаетс€.
ѕо
определению, общность hi2,† переменной i = сумме квадратов нагрузок
общих факторов. “.к. ƒисперси€ каждой i-й пере≠менной приводитс€ к 1, общность
€вл€етс€ долей единичной дисперсии, котора€ обуславливаетс€ оющими дл€
нескольких переменных факторами. ќтсюда вытекает необходимость подбора значений
общностей меньше 1. ќбщности могут принимать значени€ 0..1. ≈сть много методов
оценки hi2. ѕри большом числе переменных при неточные
оценки общностей большей частью не оказывают сильного вли€ни€ на финальное
факторное решение. 1.—пособ наибольшей коррел€ции. «аключаетс€ в выборе
наибольшего коэффициента коррел€ции данной переменной с остальными. Ётот метод
лучше использовать при большом числе переменных m (>10), но он теоретически
не обоснован. 2. »спользование квадрата коэффициентов множественной
коррел€ции.
Ri*12..i..m2-€вл€етс€ нижней
границей† hi2. Ёто наиболее
распространЄнный метод. 3. »теративна€ процедура (Ћ–3?). ѕринимаетс€ решение об
определении числа факторов r с помощью одного из методов.
34. ѕроблема вращени€ и пон€тие
наипростейшей факторной структуры.
÷ель вращени€: найти в пространстве общих факторов
одну из возможных конфигураций легко интерпретируемых факторов. онфиђгураци€ -
это система векторов, соотношени€ между которыми остаютс€ посто€нными.
—уществует три различных подхода к проблеме
вращени€:
1)√рафический. ¬ращение заключаетс€ в проведении
новых осей. которые соответствуют некоторому критерию простой, легко
интерпретируемой структуры. ≈сли в пространстве факторов есть €вные скоплени€
точек, легко отдел€емые друг от друга, проста€ структура получаетс€ в таї
случае, когда оси проведены через эти скоплени€. Ќо если такое разделение не
очевидно или число факторов велико, графический метод неприменим.
2)јналитические методы. ¬ этом случае выбираетс€
некоторый объективный критерий, которым надо руководствоватьс€ при выполнении
вращени€. ¬ рамках этого подхода различают два вида вращени€ -ортогональное и
косоугольное. ќни в свою очередь имеют многочисђленные варианты.
3)—остоит в задании априорной целевой матрицы. ÷ель
вращени€ -нахождение факторного отображени€, наиболее близкого к некоторой
заданной матрице. ÷елью всех вращений €вл€етс€ получение наиболее простой
факђторной структуры. сожалению, концепци€ простоты неоднозначна, и поэтому
не существует единых формальных критериев.
‘акторна€ структура называетс€ наипростейшей, когда
все переђменные имеют факторную сложность не больше 1, т. е. когда кажда€
переменна€ имеет ненулевую (значимую) нагрузку только на один общий фактор. ƒл€
реальных данных така€ структура недостижима. —ледова-тельно, задача состоит в
определении фактической структуры, котора€ €вл€етс€ самой Ђблизкойї к простой.
35.
÷ель
и конечный pезультат оpтогонального вpащени€.
‘ергюсон подошел к проблеме вращени€ с позиции
наибольшей простоты или экономии при описании переменных в пространстве общих
факторов. ќн исходил из того, что самое экономное описание точки в двумерном
пространстве соответствует такому ее положению, когда одна из осей проходит
через нее. —ледовательно, дл€ наиболее экономичного описани€ точек нужно при
вращении осей стремитс€ к этому идеально≠му случаю. ≈сли одна из осей
приближаетс€ к точке, то произведение двух ее координат начинает уменьшатьс€.
–ассужда€ так, он пришел к выводу, что в качестве меры экономии может служить
сумма произведений координат множества точек
Ќо
т.к. точки может иметь координаты + и -, то надо возвести в квадрат. ![]() ќн будет
стремитьс€ к минимуму, кода наибольшее кол-во точек будет лежать вблизи оси.
ќн будет
стремитьс€ к минимуму, кода наибольшее кол-во точек будет лежать вблизи оси.
ћетод
квартимакс, варимакс и модифицированный варимакс-критерий.
36. ћетоды и критерии в
ортогональном вращении.
—амое
экономное описание точки в 2-мерном пространстве, когда одна из осей проходит
через неЄ. ¬ывод, что в качестве меры экономии может служить сумма произведений
координат множества точек. Ќо т.к. точки может иметь координаты + и -, то надо
возвести в квадрат. ![]() ќн будет
стремитьс€ к минимуму, кода наибольшее кол-во точек будет лежать вблизи оси.
ћетод квартимакс не нашЄл широкого
применени€ т.к. у него сильна€ тенденци€ к выделению генерального фактора. ¬
насто€щее врем€ попул€рна его модификаци€ варимакс.
¬ этом методе было решено упростить каждый фактор (брать также и столбцы
матрицы). ¬ этом случае нагрузки близки к 1 либо 0, т.е. описываютс€ более
просто.
ќн будет
стремитьс€ к минимуму, кода наибольшее кол-во точек будет лежать вблизи оси.
ћетод квартимакс не нашЄл широкого
применени€ т.к. у него сильна€ тенденци€ к выделению генерального фактора. ¬
насто€щее врем€ попул€рна его модификаци€ варимакс.
¬ этом методе было решено упростить каждый фактор (брать также и столбцы
матрицы). ¬ этом случае нагрузки близки к 1 либо 0, т.е. описываютс€ более
просто. ![]() †
†
ћодифицированный
варимакс-критерий: ![]()
37.
÷ель
и конечный pезультат косоугольного вpащени€.
ѕервичное и вторичное факторное решение. ритерии и методы, примен€емые в
косоугольном вращении.
осоугольное
вращение более общее, чем ортогональное, так как здесь нет ограничений,
св€занных с некоррелируемостью факторов. ѕреимущество его в следующем: когда в
результате его выполнени€ получаютс€ ортогональные факторы, можно быть
уверенным, что эта ортогональность действительно им свойственна, а не внесена
моментом вращени€.
ћетод квартимин основан на введении
вторичных осей: если существуют разделимые скоплени€ точек, определ€емые
первичны≠ми факторами, то они будут иметь нулевые проекции на все вторичные
оси, за исключением одной: ![]() , где
, где ![]() †проекции i-го параметра на j-ю и k-ю вторичные оси. ¬еличина будет 0, если все параметры
имеют нагрузку только на один фактор. ÷ель вращени€-нахождение таких нагрузок,
которые минимизируют N.
†проекции i-го параметра на j-ю и k-ю вторичные оси. ¬еличина будет 0, если все параметры
имеют нагрузку только на один фактор. ÷ель вращени€-нахождение таких нагрузок,
которые минимизируют N.
ћетод коваримин (covarimin) минимизирует ковариацию квадратов
проекций на вторичные оси.
![]() .
.
ѕр€мой метод
облимин. ќснован на упрощении матрицы нагрузок первичных факторов
(без использовани€ вторичных осей). »спользуетс€ тот же самый критерий, но
вместо Vij - элементов
факторной структуры -используютс€ элементы матрицы первичного факторного
отображени€ Ц bij. ![]() .
.
ак мы видим,
возможно, представление косоугольного вращенз€ аналитически, однако в
универсальных статистических пакетах пред≠ставлены, как правило, только методы
ортогонального вращени€.
онечный
результат ‘ј-получение системы содержательно интерпретируемых факторов,
воспроизвод€щих матрицу коррел€ции(R), однако можно ещЄ сделать и измерение факторов по
значени€м наблюдаемых переменных, т.е. представить исходные данные в виде
значений полученных факторов (со снижением размерности). Ётап часто называют
факторным шкалированием. Ёто процедура, позвол€юща€ присваивать каждому объекту
некоторые числовые оценки значений выделенных факторов, использу€ значени€
наблюдаемых переменных дл€ этого объекта. Ќабор из m признаков можно анализировать либо в терминах только
общих и характерных факторов(модель компонентного анализа), либо в терминах
совокупности только общих факторов(модель ‘ј). ќсновна€ модель ‘ј: Z=A*P (Z-матрица значений
параметров(mxn), A-матрица
факторных нагрузок(mxr), P-матрица значений факторов дл€ объекта(rxn)). ћожно преобразовать это выражение дл€ более удобных
вычислений P=M-1*AT*Z. “акже, одна из задач
этого этапа-содержательна€ интерпретаци€ факторов, если мы довер€ем полученной
факторной структуре, то можно попытатьс€ произвести осмысление природы каждого
фактора, путЄм анализа общих черт переменных, имеющих высокие нагрузки на 1
фактор.†
39. ѕрограммное обеспечение,
используемое дл€ интеллектуального анализа данных.
StatSoftStatistica
ќписательные статистики и графики. √руппировка.
оррел€ции ƒиаграмма рассеивани€, матрична€ диаграмма рассеивани€, анализ по
группам. »нтерактивный веро€тностный калькул€тор. T-критерии (и другие критерии групповых различий).
SPSS
ћетоды анализа данных:ќписание данных,
ѕрогнозирование числовых результатов, —егментаци€/снижение размерности,
лассификаци€, »нструменты анализа временных р€дов.
Clementine-это автоматизированное рабочее место дл€
data mining, позвол€ющее быстро разрабатывать прогностические модели с
привлечением бизнес-экспертизы, а затем внедр€ть полученные модели дл€
усовершенствовани€ процесса прин€ти€ решений.
SAS EnterpriseMiner
ѕрограммный продукт Enterprise Miner Ц это
интегрированный компонент системы SAS, созданный дл€ вы€влени€ в огромных
массивах данных информации, необходимой дл€ прин€ти€ решений.
40. ћетоды визуализации многомерных†
данных.
Х 3ћ XYZ графики:
Ц ќтклонени€ - данные
интерпретируютс€ как координаты X, Y, Z и отображаютс€ в
трехмерном пространстве в виде "отклонений" от заданного уровн€ на
оси Z.
Ц ѕространств. -
представление данных 3ћ диаграммы рассе€ни€ при помощи плоскости XY,
расположенной на выбранном пользователем уровне вертикальной оси Z (котора€
проходит через центр плоскости).
Ц —пектральные - на таких
диаграммах в плоскости горизонтальных осей можно строить зависимость частот
спектра от последовательных временных промежутков, а на оси Z отмечать
спектральные плотности на каждом интервале.
Ц “рассировочные - точки
данных располагаютс€ так же, как и на обычных 3ћ диаграммах рассе€ни€ (значени€
переменных соответствуют координатам X, Y и Z каждой точки), но при этом
соедин€ютс€ линией (в пор€дке их следовани€ в файле данных), визуализиру€
"след" последовательных значений (например, движени€, изменени€
параметров с течением времени и т.п.).
Х
3ћ последовательные графики
Ц ƒискретные карты линий
уровн€ - 2ћ проекции€ 3ћ ленточной диаграммы. ажда€ точка данных здесь
представлена пр€моугольной областью; значени€м (или диапазонам значений точек
данных) соответствуют различные цвета и/или шаблоны областей (диапазоны указаны
в условных обозначени€х). «начени€ внутри каждой серии откладываютс€ по оси X,
а сами серии - по оси Y.
Ц ѕоверхность по исх. данным
- подогнанна€ к каждой точке данных сглаженна€ сплайнами поверхность.
ѕоследовательные значени€ каждой серии откладываютс€ по оси X, а сами
последовательные серии представлены вдоль оси Y.
Х
4ћ/“ернарные графики
Ц ††ƒиагр.рассе€ни€ - дл€ представлени€ трех (или
более) переменных [компонент X, Y и Z] на плоскости
используетс€ треугольна€ система координат. “очки графика соответствуют
пропорци€м переменных-компонент (X, Y и Z).
Ц †† арты зон - проекци€ поверхности в виде
зонной карты (подогнанной к множеству данных с четырьм€ координатами).
Ц †† арты линий - проекци€ поверхности в виде
карты линий (подогнанной к множеству данных с четырьм€ координатами).
Х
n-мерные пиктографики
Ц ††Ћица „ернова - дл€ каждого наблюдени€
рисуетс€ отдельное "лицо", где относительные значени€ выбранных
переменных представлены как формы и размеры отдельных черт лица (например,
длина носа, угол между бров€ми, ширина лица).
Ц ††—толбцы - дл€ каждого наблюдени€ рисуетс€
сво€ столбчата€ диаграмма; относительные значени€ выбранных переменных дл€
каждого наблюдени€ выражаютс€ высотами соответствующих столбцов.
Ц ††Ћинии - дл€ каждого наблюдени€ рисуетс€ свой
линейный график; относительные значени€ выбранных переменных дл€ каждого
наблюдени€ выражаютс€ высотами соответствующих точек излома над уровнем линии
основани€.
Ц †† руг. диагр. - значени€ дл€ каждого
наблюдени€ представлены в виде круговых секторов (по часовой стрелке, начина€ с
12:00); относительные значени€ выбранных переменных соответствуют площад€м
круговых секторов.
Ц ††ћногоугольн. - дл€ каждого наблюдени€ рисуетс€
свой многоугольник; относительные значени€ выбранных переменных выражаютс€
рассто€ни€ми от центра пиктограммы до соответствующих углов многоугольника (по
часовой стрелке, начина€ с 12:00).
Ц ††ѕрофили - дл€ каждого наблюдени€ рисуетс€
сво€ область; относительные значени€ выбранных переменных дл€ каждого
наблюдени€ выражаютс€ высотами соответствующих вершин контура над уровнем линии
основани€.
Ц
††«везды - дл€ каждого наблюдени€
рисуетс€ сво€ пиктограмма в виде звезды; относительные значени€ выбранных переменных
выражены относительными длинами отдельных лучей каждой звезды (по часовой
стрелке, начина€ с 12:00). онцы лучей соединены лини€ми
Ц
††Ћучи - дл€ каждого наблюдени€
рисуетс€ сво€ пиктограмма в виде солнца; каждый луч отображает одну из
выбранных переменных (по часовой стрелке, начина€ с 12:00), а длина луча равна
относительному значению соответствующей переменной. «начени€ переменных дл€
каждого наблюдени€ соединены линией.
Х
интервальные графики
Ц японские свечи - данный
метод предсказать поведение рынка в будущем оказалс€ наиболее интересным,
поскольку в одном элементе он отбражал сразу четыре показател€ вместо одного.
японцы быстро обнаружили, что на основании графиков построенных при помощи
Ђсвечейї можно с достаточной степенью веро€тности предсказывать будущий спрос и
поведение цены.
“ехнологи€ глубинного анализа
текста - Text Mining - это тот самый инструментарий, который позвол€ет анализировать большие
объемы информации в поисках тенденций, шаблонов и взаимосв€зей, способных
помочь в прин€тии стратегических решений. роме того, Text Mining - это новый вид поиска, который в
отличие традиционных подходов не только находит списки документов, формально
релевантных запросам, но и помогает ответить на вопрос: "ѕомоги мне пон€ть
смысл, разобратьс€ с этой проблематикой".
“ехнологи€ эффективного анализа
текста Text Mining преподает лишь наиболее
ключевую и значущую информацию. “аким образом, пользователю незачем самому
"просеивать" огромное количество неструктурированной информации.
–азработанные на основе статистического и лингвистического анализа, а также
искусственного интеллекта, технологии Text Mining как раз и предназначены дл€ проведени€ смыслового анализа, обеспечени€
навигации и поиска в неструктурированных текстах. ѕримен€€ построенные на их
основе системы, пользователи смогут получить новую ценную информацию - знани€.
††††††††††††††† “ак
сложилось, что наиболее часто встречаетс€ в Text Mining задача - это классификаци€ - отнесение объектов базы данных к заранее
определенным категори€м. ‘актически задача классификации - это классическа€
задача распознавани€, где по обучающей выборке система относит новый объект к
той или иной категории.
¬тора€ задача - кластеризаци€ -
выделение компактных подгрупп объектов с близкими свойствами. —истема должна
самосто€тельно найти признаки и разделить объекты по подгруппам.
ј так же анализ св€зей, которые
определ€ют по€вление дескрипторов (ключевых фраз) в документе дл€ обеспечени€и
навигации.
» извлечение фактов - которое
предназначено дл€ получени€ некоторых фактов из текста с целью улучшени€
классификации, поиска и кластеризации.
ћожно назвать еще несколько задач
технологии Text Mining, например, прогнозирование, которое состоит в том, чтобы предсказать по
значени€м одних признаков объекта значени€ остальных.
≈ще одна задача - нахождение
исключений, то есть поиск объектов, которые своими характеристиками сильно
выдел€ютс€ из общей массы. ƒл€ этого сначала вы€сн€ютс€ средние параметры
объектов, а потом исследуютс€ те объекты, параметры которых наиболее сильно
отличаютс€ от средних значений.
Ќесколько отдельно от задачи
кластеризации стоит задача поиска св€занных признаков (полей, пон€тий)
отдельных документов. ќт предсказани€ эта задача отличаетс€ тем, что заранее не
известно, по каким именно признакам реализуетс€ взаимосв€зь; цель именно в том
и состоит, чтобы найти св€зи признаков. Ёта задача сходн€ с кластеризацией, но
не по множеству документов, а по множеству присущих им признаков.
» наконец, дл€ обработки и
интерпретации результатов Text Mining большое значение имеет визуализаци€.
÷ель: извлечение полезной
информации из »нтернет.
лассификаци€:

1.
Web Usage Mining Ц вы€вление шаблонов Ђповедени€ пользователейї (доступ к страницам, переходы
навигаци€) путем анализа логов. Server logs and OLAP.
2.
Web Structure Mining Ц получение полезных знаний путем анализа структуры
гиперссылок. PageRank, SpyLog.
3.
Web Content Mining Ц добыча, извлечение и интеграци€ полезных данных, информации и знаний из
содержимого www-страницы. ѕоиск информации и извлечение
информации.